如何进行数据挖掘(数据挖掘方法与应用)

作者:宋莹
本文长度为10427字,建议阅读20 分钟
本文为你介绍数据挖掘的知识及应用。
引言
最近笔者学到了一个新词,叫做“认知折叠”。就是将复杂的事物包装成最简单的样子,让大家不用关心里面的细节就能方便使用。作为数据科学领域从业者,我们所做的事情就是用数学模型来解决实际的商业决策问题,最后包装成客户能看懂的简单图表。
笔者利用碎片化时间对“数据挖掘”这一领域知识进行了“折叠”。希望在这个碎片化的时代,对数据科学领域感兴趣的读者能够用最少的时间来学习最精华的东西。

图一:数据挖掘思维导图
一、什么是数据挖掘
简单地说,数据挖掘是指从大量数据中提取或“挖掘”知识,也叫做数据中的知识发现。
二、为什么需要数据挖掘
随着互联网工具的发展,分享和协作的成本大大降低。我们每天用手机聊天、购物、刷短视频、看新闻等日常的不经意动作给互联网行业提供了体量庞大的数据。这些数据通常被收集、存放在大型数据存储库中,没有强有力的工具,理解它们已经远远超出了我们的能力。而数据挖掘技术的出现解决了这一问题。它可以从海量的数据中提取出有价值的信息,从而作为决策的重要依据。
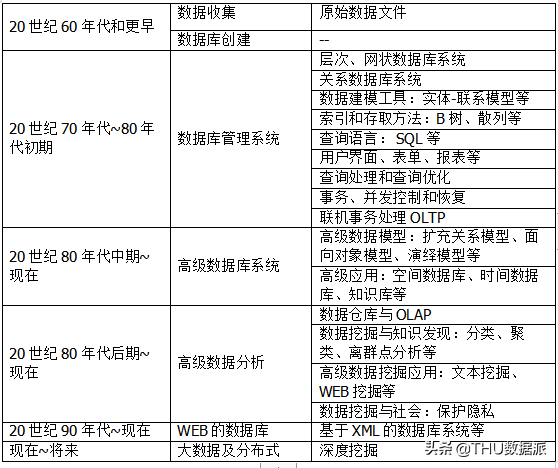
三、演化过程
柏拉图曾说过“需要是发明之母”,每一项新技术的诞生都是顺应了这个时代的发展。数据挖掘”也是信息技术自然演化的结果。如下表格展示了该演化过程。
四、数据挖掘的具体步骤
许多人把数据挖掘视为“数据中的知识发现”,以下是其具体的步骤:
- 数据清理(消除噪声和不一致数据)
- 数据集成(不同来源与格式的数据组合到一起)
- 数据选择(挖掘所需的数据)
- 数据变换(数据变换成适合挖掘的形式,如汇总,聚集操作)
- 数据挖掘(方法,建模)
- 模式评估(结果模型)
- 知识表示(可视化)
五、数据挖掘的系统结构
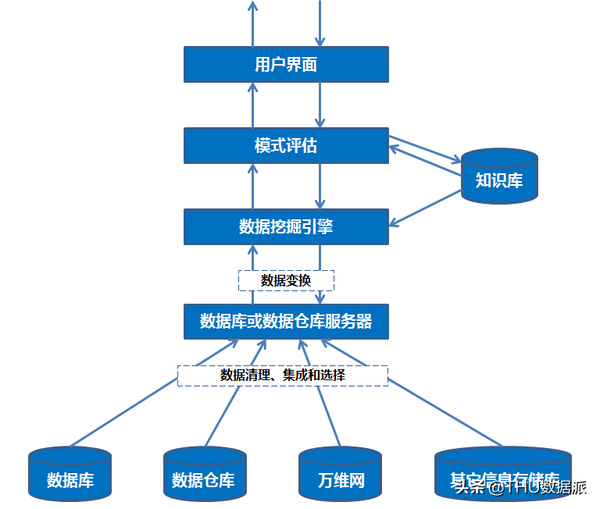
图二:数据挖掘系统结构图
六、对何种数据进行挖掘
原则上讲,数据挖掘可以应用于任何类型的信息存储库及瞬态数据(如数据流),如数据库、数据仓库、数据集市、事务数据库、空间数据库(如地图等)、工程设计数据(如建筑设计等)、多媒体数据(文本、图像、视频、音频)、网络、数据流、时间序列数据库等。
七、挖掘任务
数据挖掘功能用于指定数据挖掘任务要找的模型类型。一般而言,数据挖掘任务可以分为两类:描述和预测。描述性挖掘任务描述数据库中数据的一般性质。预测性挖掘任务对当前数据进行推断,以做出预测。其中描述类任务包含:特征化和区分等。
针对“特征化”,我们来举一个简单的例子:数据挖掘系统应当能够产生数据挖掘工程师特征的汇总描述,作为对该职位招聘的依据。结果可能是符合该职位的一般轮廓,如计算机相关专业、熟悉常用的数据挖掘算法、会使用统计分析工具、大数据开发经验等。那么,什么又是“区分”呢?继续之前的例子,数据挖掘系统应当能够描述出优秀数据挖掘工程师与一般数据挖掘工程师的轮廓。
优秀的数据挖掘工程师:超强的讲故事的能力、逻辑思维强、终身学习、喜欢用数学模型解决实际的问题。一般的数据挖掘工程师:了解常用数据挖掘算法、对工作能够积极完成、对挖掘结果无法清晰描述给相关人、不会主动学习该行业知识、从事此行业只是为了赚钱。这两个轮廓将作为我们评判优劣的依据。预测类任务为:关联分析、分类和预测、聚类分析、孤立点分析和趋势和演变分析等。下面章节的实例将介绍其中某些预测类模型。在这里就不再赘述。
八、挖掘什么模式的数据
1.易于理解的。
2. 在某种程度上,对于新的或检验数据是有效的。
3. 潜在有用的。
4. 新颖的。
5. 客观度量(支持度,置信度)。
6. 用户想要了解的,对用户有价值的。
九、数据挖掘的局限性
数据科学家吴军老师在《数学之美》一书中强调数学之所以美,是因为数学的简单性。我们的计算机基础就是布尔代数,其运算元素只由0,1组成。虽然数学如此简单,但其在各个领域的作用却不容忽视。它可以帮助我们发现仅凭经验无法发现的规律,找到仅凭经验无法总结出来的办法。因此在这个大数据时代,以数学为基础的数据挖掘领域常常会被大家神话。
认为现在的数据体量足够大,支持的异构数据种类越来越多,信息的数据化程度越来越完善,分布式的框架也给大数据的深度挖掘提供了有力支持,数据挖掘结果也就会越来越精准。其实不然,虽然这些有力条件提高了数据预测能力,但是毕竟还有很多事物暂时还无法数据化。比如人的思维,同时还有互联网没有采集到的人们的日常活动等。这些未被采集的信息,会导致我们挖掘的结果有偏差,甚至完全不可用。并且单一化的数学工具挖掘出的结果通常都比较片面。因此就需要我们建立多元化思维,在进行挖掘的时候要按照“T”型结构。
所谓“T”型结构就是利用现如今的有利条件进行纵向深度挖掘,同时也要横向扩展多学科知识。未来的数据挖掘领域,绝不是单一的数学一门单一学科就能搞定,而是多学科结合,综合考虑得出结论。
十、数据挖掘实例
1.准备工作
为了让大家更直观的了解数据挖掘的整个流程,我将该实例中需要用到的软件,以及如何安装、配置的过程整理出来,作为实例开始前的准备工作。我选取的是数据挖掘工具Rapidminer。之所以选择此工具,是由于它的便捷性,用拖拽的方式就可以进行分析挖掘,而本篇文章的侧重点是想展示数据挖掘的整个流程。这个工具无疑是最好的选择。
- 1.1Rapidminer工具简介
Rapidminer是一款预测性分析和数据挖掘软件。它的特点是拖拽操作,无需编程,运算速度快,有开源版和商业版。它具有丰富数据挖掘分析和算法功能。常用于解决各种的商业关键问题。如营销响应率、客户细分、客户忠诚度及终身价值、资产维护、资源规划、预测性维修、质量管理、社交媒体监测和情感分析等典型商业案例。解决方案覆盖了各个领域,包括汽车、银行、保险、生命科学、制造业、石油和天然气、零售业及快消行业、通讯业、以及公用事业等各个行业。
编程:
https://baike.baidu.com/item/编程
- 1.2Rapidminer安装
我们需要登录rapidminer的官网来下载这个数据挖掘工具,如下是该网址:
https://rapidminer.com/get-started/
登录后我们会看见如下所示的下载界面,在此页面上填写个人邮箱信息等信息,然后点击download按钮。

图三:rapidminer下载界面
在downloads页面,选择适合自己操作系统的安装包即可下载。下载后直接点击安装即可。
图四:不同操作系统的不同安装包
- 1.3Rapidminer配置
rapidminer软件安装成功后,点击桌面的软件图标,即可打开该软件,由于我们的实例要进行数据库的读写操作。因此,我们需要创建一个数据库连接,笔者提前在电脑上安装了mysql数据库,数据库的安装过程超出了此文章的范围,读者需要提前安装一个数据库,不限于mysql。
如下所示,我们在界面左侧的数据库连接处进行数据库连接的创建。并填写数据库信息,最后进行连接测试,当像图七一样显示“Test successful”时,说明已经配置好了。
图五:创建数据库链接
图六:数据库连接名
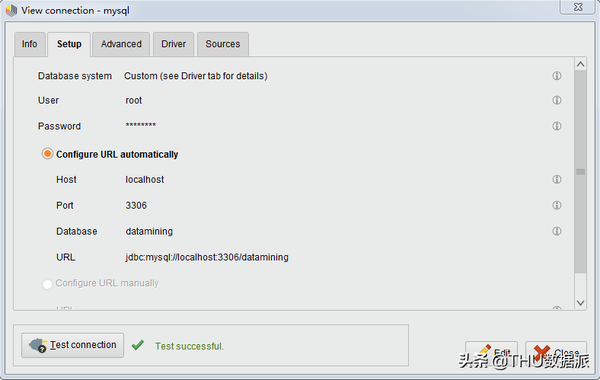
图七:数据库信息
2.数据挖掘实例演示
下面我们利用Rapidminer数据挖掘工具,按照CRISP-DM(数据挖掘标准流程)来进行数据挖掘的实例演示。
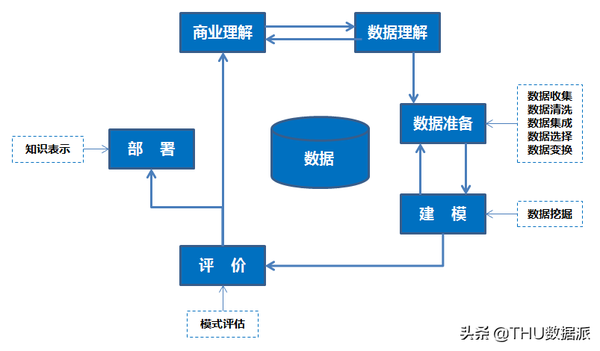
图八:数据挖掘标准流程
- 2.1商业理解
为了让大家体验真实的、完整的数据挖掘流程。我对一个真实的商业问题做了一个市场调查。并通过这个市场调查结果进行分析。要想把这个商业问题说清楚,我必须在这里介绍一下我的情况。
去年年底,我的女儿出生了。由于家里无人可以帮忙照顾,只好辞职在家全职带宝宝。也跟大多数的全职妈妈一样,成为了一个名副其实的微商。由于本人特别喜欢看书,就在微信上做起了卖书的小生意。我的生意以童书为主。在卖书的过程中,我发现爱给孩子买书的家长大多数自己本身就喜欢看书或者有学习意识。为了更精准的定位我的目标客户。我设计了一份专门针对宝妈的调查问卷,目的就是要研究爱学习的宝妈身上都有哪些特质。根据这些特质去有针对性的寻找我的目标客户,进而提高销量。
- 2.2数据理解
在“宝妈情况问卷调查”中,我设计了20个与宝妈日常生活息息相关的问题,其具体内容如下:
1.姓名(m_name):调查者的姓名。由于本篇文章会在公众平台上发表,对姓名我会做脱敏处理,只留下“姓”作为区分宝妈的依据,如:“吴军”会被展示成“吴**”。
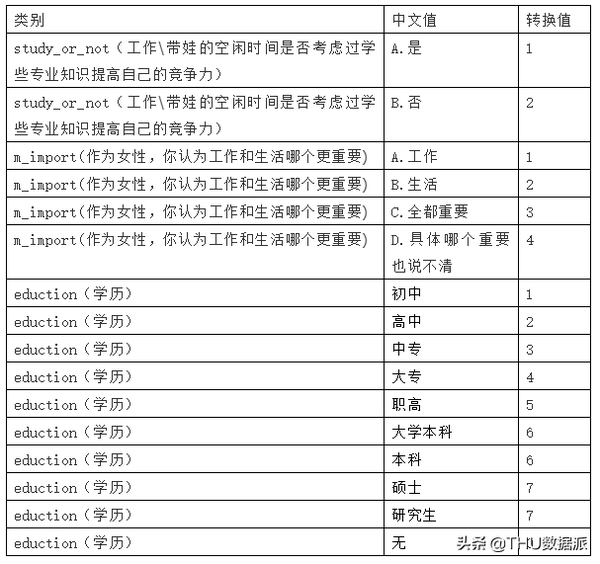
2.学历(eduction):调查者的学历信息。
3.专业(major):调查者的专业信息。
4.年龄(age):调查者的年龄。
5.工作年限(work_seniority):调查者的工作年限。
6.工作岗位(m_work):调查者的工作岗位。
7.孩子小名(nickname):宝宝的小名。由于孩子真实姓名也比较敏感,所以这里只填写小名。
8.孩子年龄(child_age):宝宝的年龄。
9.孩子性别(child_sex):宝宝的性别。
10.你认为自己家的孩子是否好带(care_level):
1——4,1表示好带,4表示特别不好带。
选项A.1 B.2 C.3 D.4
11.你现在当前的状态(state_now):
A.全职在外工作 B.兼职在外工作 C.兼职在家 D.全职带娃 E.其它
12. 如果是自己带娃,其原因(myself_care_reason):
A.无人给带 B.别人带娃不放心 C.特别想自己带 D.其它
13. 作为女性,你认为工作和生活哪个更重要(m_import):
A.工作 B.生活 C.全都重要 D.具体哪个重要也说不清
14. 如果有别人给带娃,那个人是谁(care_child_people):
A.爸爸妈妈 B.公公婆婆 C.其它亲戚 D.育儿嫂
15. 如果爸爸妈妈或公公婆婆想把孩子带老家养,什么都不用你们管,是否同意(go_home_or_not):
A.同意 B.不同意
16. 工作\带娃的空闲时间是否考虑过学些专业知识提高自己的竞争力(study_or_not):
A.是 B.否
17. 有没有学习过专业的育儿经验(
parenting_knowledge_or_not):
A.学过 B.没学过
18. 是否认为自己是一个称职的妈妈(qualified_mothers_or_not):
A.称职 B.不称职
19.如果有一个网站专门提供在家上班的工作,工作不耽误带娃,薪资水平也也不错,是否考虑注册一个账号,并在上面找一个合适的工作(work_home_or_not):
A.考虑 B.不考虑
20. 作为宝妈,你是否有时候感觉自己心情很低落,像是得了抑郁症,很需要别人进行情感疏导(mothers_mood):
A.有 B.没有,心情一直很好
- 2.3数据准备
在接下来的数据准备阶段,大家可以按照如下地址来下载所需的数据:
https://pan.baidu.com/s/145ljBAR2V0bG8FcXGL3j9A
- 2.3.1数据收集
我通过调查问卷的形式进行了数据收集,以纸质问卷和腾讯问卷两部分组成,来模拟不同数据来源。纸质问卷的调查地点选择了人流量比较大的商场。如下是调查问卷中的一份:
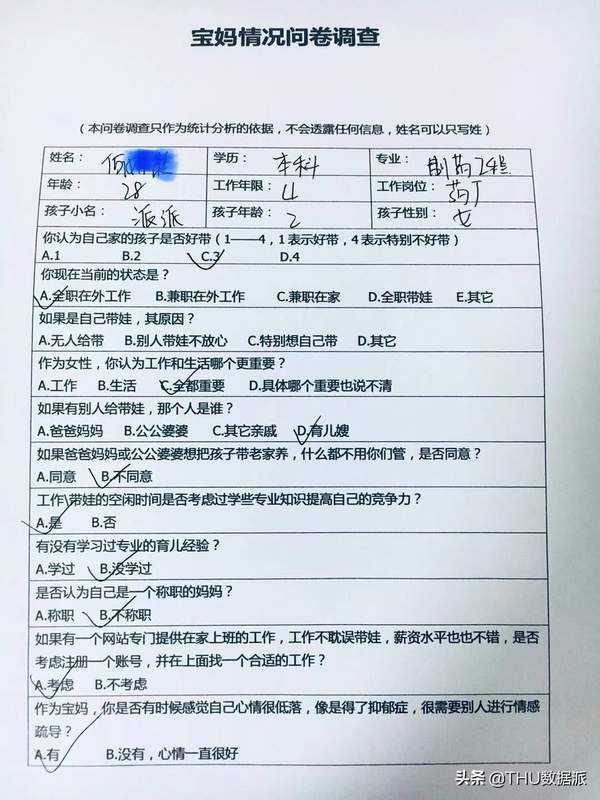
图九:宝妈情况问卷调查
腾讯问卷是在微信上进行收集的。如下是腾讯问卷调查的部分结果截图,姓名已做脱敏处理。
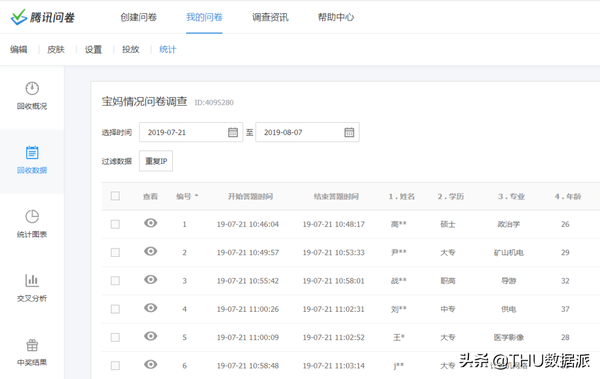
图十:宝妈情况问卷调查-腾讯问卷
由于纸质的调查问卷无法用来直接分析,因此我将问卷的结果整理到了excel中。如下是整理好的纸质调查问卷部分截图。excel文档的名字叫做“纸质调查问卷.xlsx”
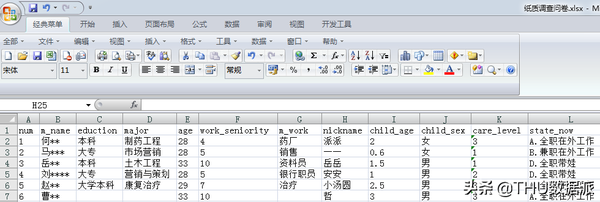
图十一:纸质调查问卷
腾讯问卷部分,可以直接在线导出CSV格式。如下是导出的CSV文件中的部分数据截图。

图十二:腾讯问卷
同时,我观察到腾讯问卷的导出结果已将选择题的A,B,C,D选项结果转换成了数字1,2,3,4。为后续的分析工作提供了方便。对比如下:
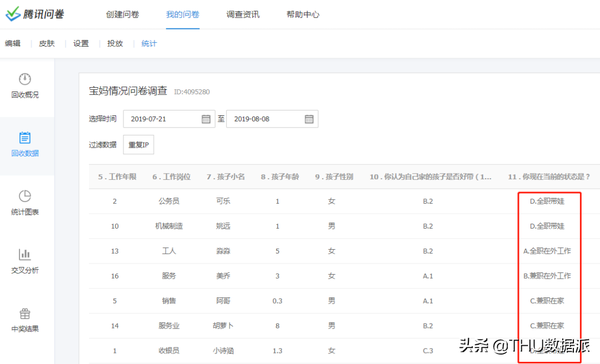
图十三:腾讯问卷原始文件截图
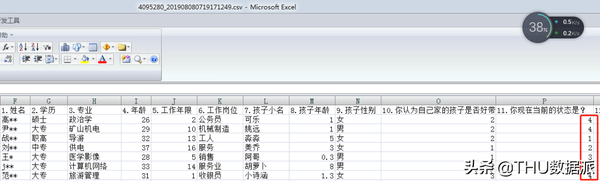
图十四:腾讯问卷导出csv后的文件
为了看起来方便,我们把导出的CSV文件名称改成“腾讯问卷结果.csv”
- 2.3.2数据清洗
1.在Rapidminer中新建一个流程,名字叫“1纸质问卷数据清洗过程”。这个流程的主要目的就是对纸质调查问卷数据进行清洗工作。具体情况如下所示:

图十五:新建流程“1纸质问卷数据清洗过程”目录
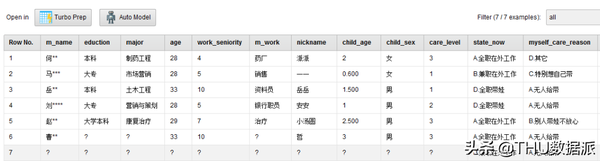
图十六:纸质调查问卷部分内容
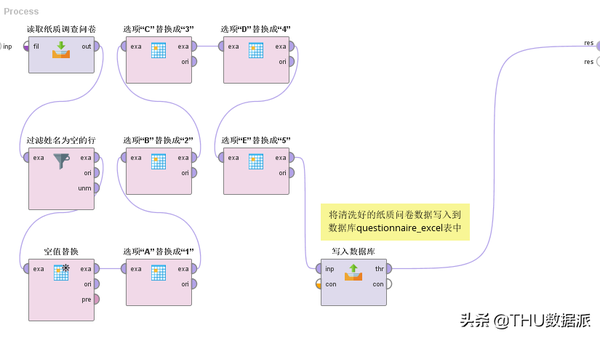
图十七:流程“1纸质问卷数据清洗过程”
纸质问卷数据清洗过程解读:
(1)“读取纸质调查问卷”的作用是将“纸质调查问卷.xlsx”文档中的内容读入Rapidminer中。(read excel控件)
(2)“过滤姓名为空的行”的作用是过滤掉“图十六:纸质调查问卷部分内容”中的第七行内容,该行缺少很多必要信息,不适合做分析。
(3)“空值替换”的作用是将“图十六:纸质调查问卷部分内容”中eduction、major、m_work列里的空值替换成默认的“无”。( Reolace Missing Values控件)
(4)“选项A替换成1”、 “选项B替换成2”、 “选项C替换成3”、 “选项D替换成4”、 “选项E替换成5”的作用是将“图十六:纸质调查问卷部分内容”中state_now以后(包含state_now)(filter Examples控件)的字段中含有A、B、C、D、E选项的内容转换成1、2、3、4、5,便于后续模型的创建,及与腾讯问卷的导出结果保持一致。(Reolace控件)
(5)“写入数据库”的作用是将清洗好的“纸质调查问卷.xlsx”数据存入数据库questionnaire_excel表中。(Write Database控件)
2.在Rapidminer中新建一个流程,名字叫“1腾讯问卷数据清洗过程”。这个流程的主要目的就是对腾讯调查问卷数据进行清洗工作。具体情况如下所示:
图十八:新建流程“1腾讯问卷数据清洗过程”目录
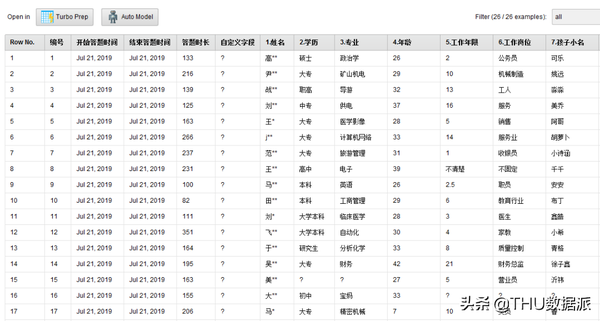
图十九:腾讯调查问卷部分内容
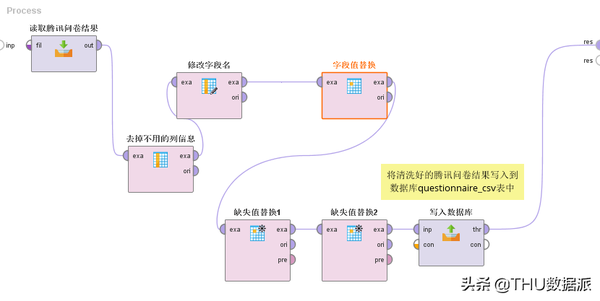
图二十:流程“1腾讯问卷数据清洗过程”
腾讯问卷数据清洗过程解读:
(1)“读取腾讯问卷结果” 的作用是将“腾讯问卷结果.csv”文档中的内容读入Rapidminer中。(Read CSV控件)
(2)”去掉不用的列信息”的作用是将“图十九:腾讯调查问卷部分内容”中的编号、开始答题时间、结束答题时间、答题时长、自定义字段这5列信息去掉,因为这5列信息不是我们挖掘关注的指标。(Select Attributes控件)
(3)“修改字段名”的作用是将“图十九:腾讯调查问卷部分内容”中的中文字段名改成与纸质调查问卷一样的字段名。如”1.姓名”改成”m_name”。( Rename控件)
(4)“字段值替换”的作用是将“图十九:腾讯调查问卷部分内容”中第八行、“5.工作年限”(work_seniority)列的“不清楚”替换成空值。(Reolace控件)
(5)“缺失值替换1”的作用是将“图十九:腾讯调查问卷部分内容”中“2.学历”、“3.专业”、”6.工作岗位”、“7.孩子小名”、“9.孩子性别”列的空值转换成默认值“无”,以及将“5.工作年限”、“8.孩子年龄”中的空值转换成该列的平均值。( Reolace Missing Values控件)
(6)“缺失值替换2”的作用是将“图十九:腾讯调查问卷部分内容”中“12.如果是自己带娃,其原因?”中的空值转换成“4”4的含义是“其它”。( Reolace Missing Values控件)
(7)“写入数据库”的作用是将清洗好的腾讯问卷结果写入数据库questionaire_csv表中。(Write Database控件)
- 2.3.3数据集成
1.在Rapidminer中新建一个流程,名字叫“2数据集成”。这个流程的主要目的就是将纸质问卷与腾讯问卷清洗好的数据进行整合。为下面的建模做准备。具体情况如下所示:
图二十一:新建流程“2.数据集成”目录
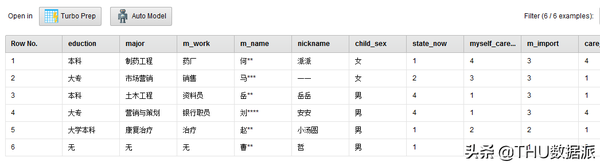
图二十二:流程“1纸质问卷数据清洗过程”结果
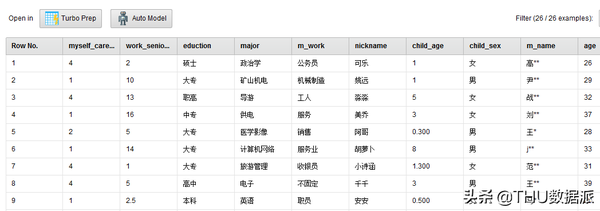
图二十三:流程“1腾讯问卷数据清洗过程”结果
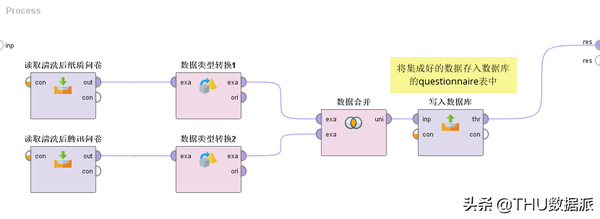
图二十四:流程“2.数据集成”
数据集成解读:
(1)“读取清洗后纸质问卷”的作用是将流程“1纸质问卷数据清洗过程”(在数据库questionnaire_excel表中存放)的结果读取出来。(Read Database控件)
(2)“读取清洗后腾讯问卷”的作用是将流程“1腾讯问卷数据清洗过程”(在数据库questionnaire_csv表中存放)的结果读取出来。(Read Database控件)
(3)“数据类型转换1”的作用是将清洗后的纸质问卷数据的数据类型进行调整,如:state_now(当前状态)字段,清洗前是含有A、B、C、D选项的字符型。清洗后变成含有1、2、3、4选项的数值型。(Guess Types控件)
(4)数据类型转换2”的作用是将清洗后的腾讯问卷数据的数据类型进行调整,如:work_seniority(工作年限)字段,清洗前是含有“不清楚”字样的字符型,清洗后变成数值型。(Guess Types控件)
(5)“数据合并”的作用是将纸质问卷与腾讯问卷数据进行整合。(Union控件)
(6)“写入数据库”的作用是将整合后的数据存入数据库的questionnaire表中。(Write Database控件)
- 2.3.4数据选择
1.在Rapidminer中新建一个流程,名字叫“3数据选择”。这个流程的主要目的就是选择建模需要用到的列,将不需要的列筛选下去。具体情况如下所示:
图二十五:新建流程“3.数据选择”目录
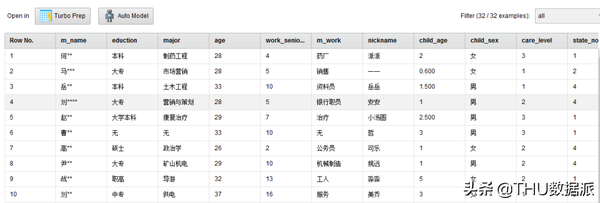
图二十六:流程“2数据集成”结果
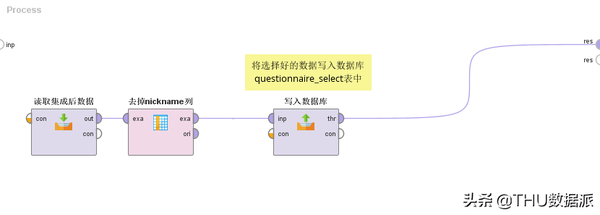
图二十七:流程“3.数据选择”
数据选择解读:
(1)“读取集成后数据”的作用是将流程“2数据集成”(在数据库questionnaire表中存放)的结果读取出来。(Read Database控件)
(2)“去掉nickname列”的作用是将nickname(孩子小名)列去掉。保留其它列信息,主要原因是此列对所要研究的问题建模没有意义。(Select Attributes控件)
(3)“写入数据库”的作用是将选择好的数据写入数据库questionnaire_select表中。(Write Database控件)
- 2.3.5数据变换
1.在Rapidminer中新建一个流程,名字叫“4数据变换”。这个流程的主要目的就是将eduction、major、m_work及child_sex列中的类别变换成数字,便于建模。具体情况如下所示:
图二十八:新建流程“4.数据变换”目录
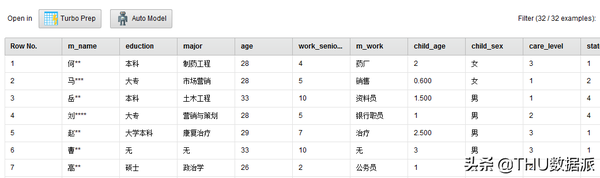
图二十九:流程“3数据选择”结果
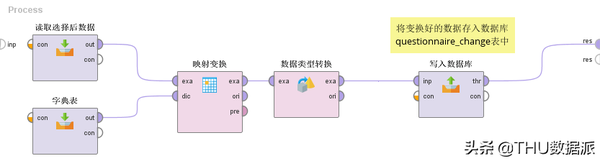
图三十:流程“4数据变换”
数据变换解读:
(1)“读取选择后数据”的作用是将流程“3数据选择”(在数据库questionnaire_select表中存放)的结果读取出来。(Read Database控件)
(2)“字典表”的作用是将数据库中新建的eduction、major、m_work及child_sex列与数字的映射关系读取出来。(Read Database控件)
(3)“映射变换”的作用是将eduction、major、m_work及child_sex列根据字典表的映射关系,转换成数字。(Replace (Dictionary))
(4)“数据类型转换”的作用是将eduction、major、m_work及child_sex列的数据类型由字符型转换成数值型。(Guess Types控件)
(5)“写入数据库”的作用是将变换好的数据存入数据库questionnaire_change表中。(Write Database控件)
其中学历信息映射:


其中专业信息映射:
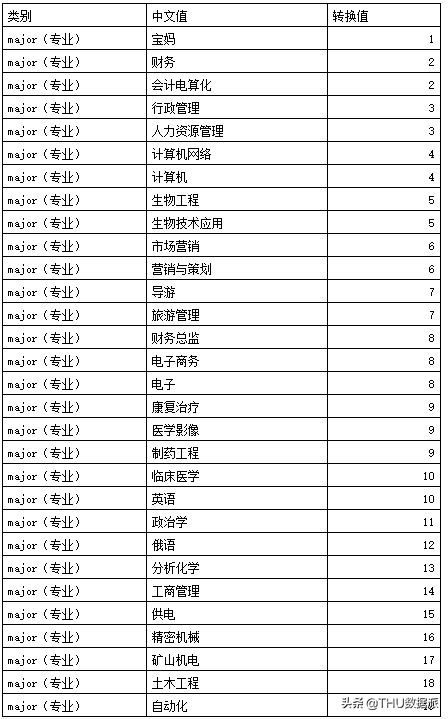
其中工作岗位信息映射:
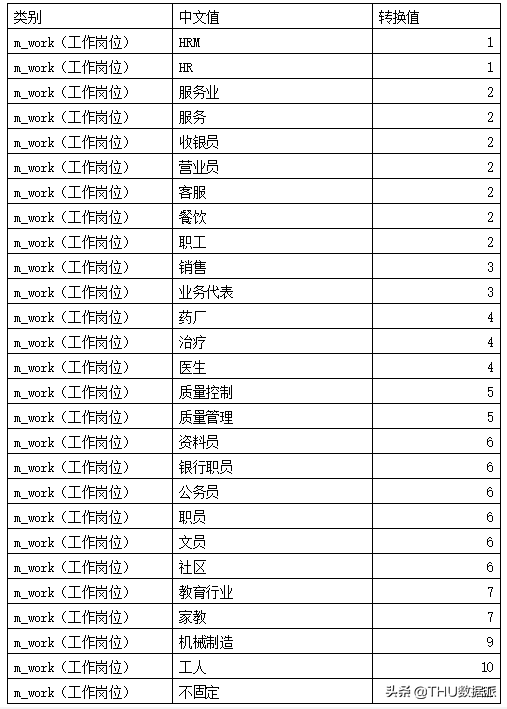
其中孩子性别信息映射:

- 2.3.6离群点分析
1.在Rapidminer中新建一个流程,名字叫“5离群点分析”。这个流程的主要目的是分析数据中是否有不和规范的数据。主要看分析出来的离群点是真的有问题,还是有新发现。具体情况如下所示:

图三十一:新建流程“5离群点分析”目录

图三十二:流程“4数据变换”结果
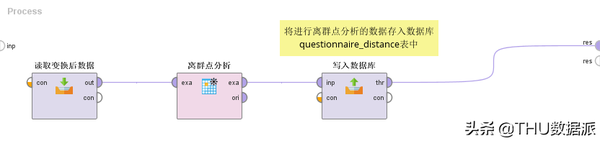
图三十三:流程“5离群点分析”

图三十四:离群点分析结果
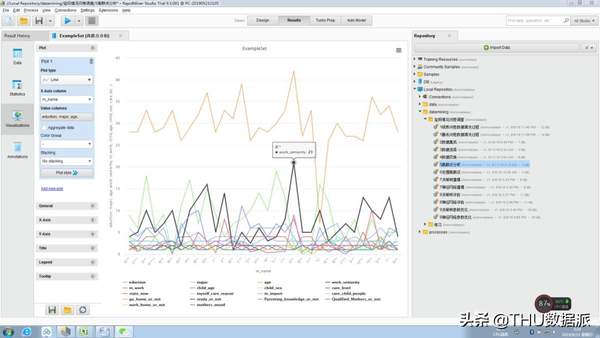
图三十五:离群点分析图表展示1
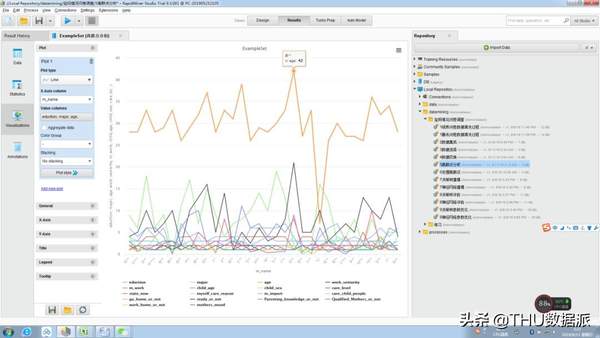
图三十六:离群点分析图表展示2
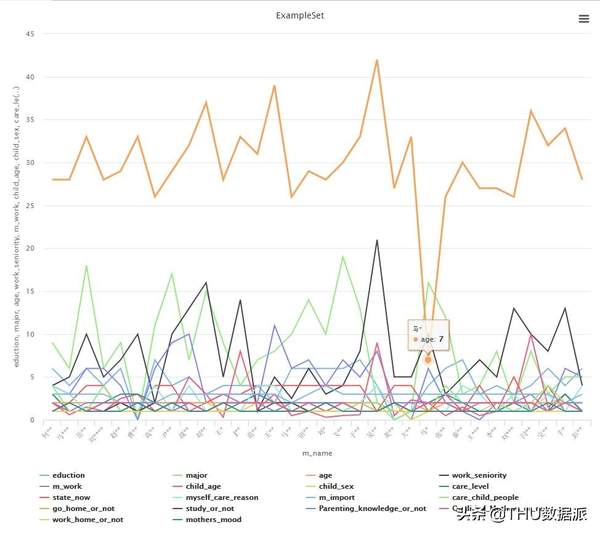
图三十七:离群点分析图表展示3
离群点分析解读:
(1)“读取变换后数据”的作用是将流程“4数据变换”(在数据库questionnaire_change表中存放)的结果读取出来。(Read Database控件)
(2)“离群点分析”的作用是找出数据表中的离群点,并标记出来。这里可以设置需要找多少个离群点,因为我们的样本数据比较少,所以笔者设置标记2个离群点数据。(Detect Outlier (Distances)控件)
(3)“写入数据库”的作用是将经过离群点分析后的数据写入到数据库questionnaire_ distance表中。(Write Database控件)
执行流程后,找到了2个离群点如“图三十四:离群点分析结果”所示。
其中“吴**”如图“图三十五:离群点分析图表展示1”与“图三十六:离群点分析图表展示2”所示工作年限21年,比其它人的工作年限都长,但是这个人的年龄同时也很大,所以这个离群点是合理的。不用对它进行处理。
另一个“马*”如图“图三十七:离群点分析图表展示3”所示,她的年龄是7岁,7岁的宝妈,显然数据有问题,笔者猜测这个被调查者有可能是想写27岁。
- 2.3.7处理离群点
1.在Rapidminer中新建一个流程,名字叫“6处理离群点”。这个流程的主要目的是将有问题的离群点数据进行处理,没问题的离群点进行保留。具体情况如下所示:
图三十八:新建流程“6处理离群点”目录
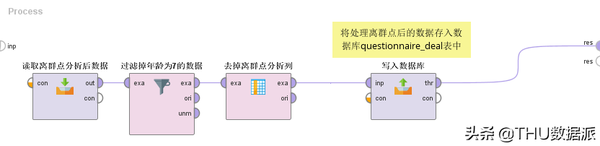
图三十九:流程“6处理离群点”
处理离群点解读:
(1)“读取离群点分析后数据”的作用是将流程“5离群点分析”(在数据库questionnaire_distance表中存放)的结果读取出来。(Read Database控件)
(2)“过滤掉年龄为7的数据”的作用是将流程“5离群点分析”中的异常点过滤掉。(filter Examples控件)
(3)“去掉离群点分析列”的作用是将流程“5离群点分析”中用于标记离群点的outlier列去掉。(Select Attributes控件)
(4)“写入数据库”的作用是将处理离群点后的数据存入数据库questionnaire_deal表中。(Write Database控件)
- 2.4.建模
- 2.4.1决策树
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。
基础:
https://baike.baidu.com/item/基础/32794
期望:
https://baike.baidu.com/item/期望/35704
- 2.4.2决策树建模
1.在Rapidminer中新建一个流程,名字叫“7决策树建模”。这个流程的主要目的是对所提出的问题进行建模,从而对问题进行预测。具体情况如下所示:
图四十:新建流程“7决策树建模”目录

图四十一:流程“6处理离群点”结果
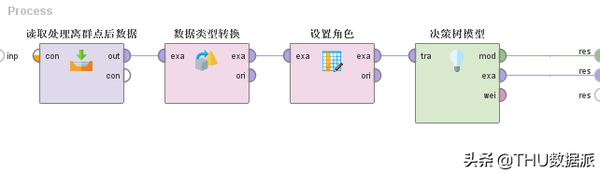
图四十二:流程“决策树建模”
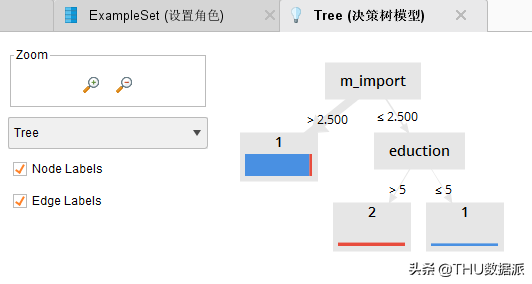
图四十三:决策树模型运行结果

图四十四:决策树模型结果描述
决策树建模解读:
(1)“读取处理离群点后数据”的作用是将流程“6处理离群点”(在数据库questionnaire_deal表中存放)的结果读取出来。(Read Database控件)
(2)“数据类型转换”的作用是将要预测的study_or_not(空闲时间是否学习)字段的数据类型转换成字符型。(Numerical to Polynominal控件)
(3)“设置角色”的作用是将m_name(姓名)列的角色设置成ID唯一标识,并且将study_or_not(空闲时间是否学习)列设置成label标识(rapidminer中需要将预测列标识成label字段才可以执行流程)。(Set Role控件)
(4)“决策树模型”的作用是应用该模型对现有数据进行预测。如图“图四十三:决策树模型运行结果”是决策树模型的运行结果。(Decision Tree控件)
- 2.5.评价
- 2.5.1决策树模型评估
1.在Rapidminer中新建一个流程,名字叫“8决策树评估”。这个流程的主要目的是由于建模过程形成的众多结果,我们没有办法去判断哪个模型最符合现实的情况,因此,我们需要对所建的模型进行评估,通过评估结果来选择预测最准确的那个模型。具体情况如下所示:
图四十五:流程“8决策树评估”目录

图四十六:流程“8决策树评估”

图四十七:流程“8决策树评估”2

图四十八:模型评估控件参数设置
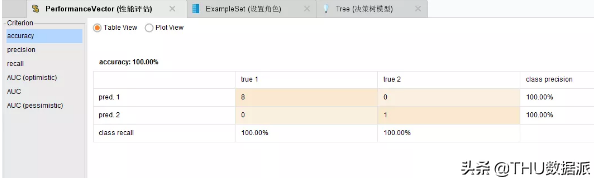
图四十九:决策树评估结果
决策树评估解读:
(1)“读取处理离群点后数据” 的作用是将流程“6处理离群点”(在数据库questionnaire_deal表中存放)的结果读取出来。(Read Database控件)
(2)“数据类型转换”的作用是将要预测的study_or_not(空闲时间是否学习)字段的数据类型转换成字符型。(Numerical to Polynominal控件)
(3)“设置角色”的作用是将m_name(姓名)列的角色设置成ID唯一标识,并且将study_or_not(空闲时间是否学习)列设置成label标识(rapidminer中需要将预测列标识成label字段才可以执行流程)。(Set Role控件)
(4)“模型评估”的作用是对不同的模型进行训练,然后对训练好的模型进行测试。该模型内部也有一个流程,主要是进行模型训练,最后对训练好的模型进行评估。此外如图“图四十八:模型评估控件参数设置”训练数据和测试的分配比率设置成了0.7,也就是说这个控件将数据的70%当成训练数据,30%当成测试数据。来对这个模型进行评估。(Split Validation控件)
(5)“决策树模型”的作用是应用该模型对现有数据进行预测。如图“图四十三:决策树模型运行结果”是决策树模型的运行结果。(Decision Tree控件)
(6)“模型应用”的作用是按照现有的训练好的模型对测试数据进行预测。(Apply Model控件)
(7)“性能评估”的作用是应用一系列标准值对模型进行评估。如图“图四十九:决策树评估结果”所示,决策树模型准确率是100%。(Performance控件)
6.部署
- 6.1可视化展示
如下图所示,是决策树模型的可视化结果。
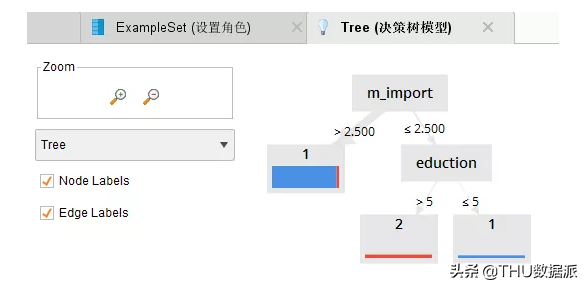
图五十:决策树模型运行结果
图五十一:决策树模型结果描述
7.小结
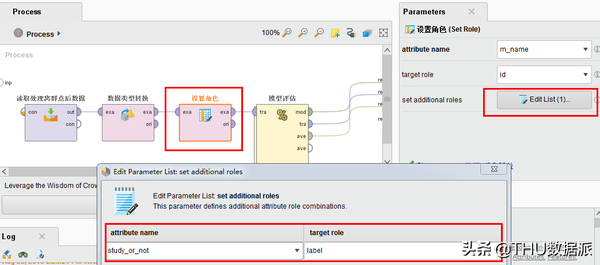
图五十二:决策树评估中设置的角色
通过图“图五十二:决策树评估中设置的角色”中我们可以看出,我们将study_or_not字段设置成了label标签属性,在Rapidminer中,我们把哪个指标设置成label属性,我们分析的就是哪个指标。也就是笔者想要分析的“工作\带娃的空闲时间是否考虑过学些专业知识提高自己的竞争力”。并且通过上面的映射表可以看出study_or_not等于1是会利用业余时间学习的人,等于2是业余时间不学习的人。
通过图“图五十:决策树模型运行结果”及图“图五十一:决策树模型结果描述”可以很直观的看到,当m_import(作为女性,你认为工作和生活哪个更重要)>2.5时有25个人会利用业余时间学习、1个人业余时间不学习。通过观察数据,会发现m_import大于2.5的数据都是3(C.全都重要)。接下来我们来看决策树的另一个分支:当m_import(作为女性,你认为工作和生活哪个更重要)<=2.5的时候,通过观察数据,会发现m_import小于等于2.5的数据是1和2的(1.工作,2.生活)。我们的数据还需要进一步判断eduction(学历)。当eduction学历大于5时没有人利用业余时间学习、3个人业余时间不学习。当eduction(学历)小于等于5时2个人利用业余时间学习、没有人业余时间不学习。通过上面表格可以看出eduction(学历)小于等于5的是本科以下学历的。< p="">
综上所述,笔者想要找到爱学习的宝妈,通过模型可以看出爱学习的宝妈有两部分组成,一部分是认为工作与生活全都重要的人。另一部分是认为工作、生活有一个重要,并且学历在本科以下的人。
编辑:王菁
校对:文婧、林亦霖
作者简介

宋莹,数据派研究部志愿者,毕业渤海大学信息与计算科学专业,现就职深圳长亮科技股份有限公司。投身于商业智能、数据分析及大数据领域7年多,对用数据模型解决实际问题有浓厚兴趣,希望结实志趣相投的伙伴。
— 完 —
关注清华-青岛数据科学研究院官方微信公众平台“THU数据派”及姊妹号“数据派THU”获取更多讲座福利及优质内容。