微服务面临的挑战(微服务高并发处理方案)

作者 | Igor Perikov
译者 | 陆离
责编 | 徐威龙
出品 | CSDN云计算(ID:CSDNcloud)
在本文中,我将介绍微服务中的几种容错机制及其实现的方法。如果你在维基百科上查找“容错性”,你将会发现有如下的定义:
“容错性是一种特性,它使系统能够在某些组件发生错误时仍能继续正常地运行。”
对于我们来说,一个组件意味着很多:微服务、数据库(DB)、负载均衡器(LB),你可以给它命个名。我在这里不讨论数据库和负载均衡器的容错机制,因为它们是特定于供应商的,并且如果使用它们的话,需要设置一些属性或者更改部署策略。
作为一个软件工程师,应用程序是我们展现自身力量和承担责任的地方。下面,我将从以下几个方面进行介绍容错性:
- 超时(Timeouts)
- 重试(Retries)
- 熔断机制(Circuit Breaker)
- 截止时间(Deadlines)
- 限流器(Rate limiters)
有些模式是广为人知的,你甚至可能都会觉得有些不值得一提,但也请紧跟本文的思路,我将要简要介绍这几个基本的容错方法,然后一一讨论它们的缺点以及应该如何避免。
超时
超时是指允许等待某个事件发生的指定时间范围。如果使用SO_TIMEOUT(也称为socket timeout或read timeout)参数则会出现问题,它表示任何两个连续数据包之间的超时,而不是整个请求的响应时间,因此很难满足SLA(Service-Level Agreement,服务等级协议),特别是在应用服务响应负载很大的情况下。通常来说,我们所说的超时,是覆盖了从建立请求连接到响应最后一个字节完成的整个交互过程。不过,它们不适合使用SO_TIMEOUT参数。想要在JVM中避免使用它,可以使用JDK11或是OkHttp客户端。Go语言在std库中也有一个相关的机制。
重试
如果你的请求失败了,那么请稍等一会儿,然后再试一次。重试的过程基本上就是这样的。重试是有意义的,因为网络可能会降级服务一段时间,或者GC(垃圾回收)会命中请求所到达的特定实例。现在,让我们来想象有如下所示的服务调用过程:
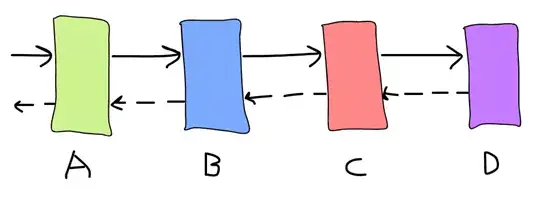
如果我们将每个服务的请求尝试次数上限设置为3,并且服务D突然发生完全中断的错误,那么会发生什么情况呢?这将导致一场请求重试风暴,当服务链中的每个服务开始重试它们的请求时,会由此大大增加了总负载量,所以服务B将面临担负是通常情况下3倍的请求负载,C是9倍,而D是27倍。冗余是实现高可用性的关键原则之一,但我怀疑在这种情况下,集群C和D上是否还有足够的空闲资源。将尝试次数上限设置为2也不会有多大帮助,而且它会使在较小blip上的用户体验会更糟。
解决方案:
- 区分可重试错误和不可重试错误。当用户没有权限或负载结构不正确时,重试请求是没有意义的。相反,重试请求超时或返回代码5xx是没有问题的;
- 设置错误重试机制。当重试错误次数超过阈值时停止重试,例如,与服务D进行交互,如果20%的结果都是错误的,则停止重试并尝试降级服务。在过去的N秒内,可以使用滚动窗口跟踪错误量;
熔断机制
熔断器可以作为一个更严格的错误率预置方案。当错误率过高的时候,任务将不会继续执行,如果提供了回退结果,那么就会返回。无论如何,首先应该选择先执行很少的一部分请求,以便了解目标服务是否已经恢复了。在人工干预之前,我们应该给目标服务一个自己恢复的机会。
你可能不太赞同上述的方法,如果一个功能处于关键路径上,启用熔断器是没有意义的,但不要忘了,这种短暂的、可控的“自动断电”可能会阻止一次大的、不可控的服务中断。
尽管熔断机制和错误重试机制有着相似的想法,但是它们在实际应用的过程中是非常有意义的。由于错误重试机制的破坏性较小,因此,其阈值尽量要设的低一些。
Hystrix是一个在JVM中的go-to模式熔断机制的实现。到目前为止,它已经进入了维护模式,建议使用resilience4j来替代。
截止时间/分布式超时
我们已经在本文的第一部分讨论了超时模式,现在让我们看看如何实现它们的“分布式”。首先,再一次访问相互调用的一系列服务链:

服务A最长可以等待400毫秒,并且一个请求需要依次调用3个下游服务才能完成任务。假设对服务B的请求和响应花了400毫秒,下一步就准备调用服务C。那么,这种情况是不合理的,一旦服务超时,就不应该再等待任何结果。如果继续下去只会浪费资源,增加请求重试风暴发生的风险。
为了实现这个过程,我们必须在请求中添加额外的元数据,这将有助于理解在什么时候进行中断处理是最合理的。理想情况下,这应该得到所有服务的支持,并在整个调用流程中进行参数的传递。
在实际的过程中,上述元数据可以分为以下几种形式:
- Timestamp(时间戳):是通过服务停止等待响应的时间点。首先,网关或者前端服务将截止时间设置为“当前时间戳 超时”。接下来,任何下游服务都应该检查当前时间戳是否超过了截止时间。如果超过了,那么要停止响应,否则,就开始处理。遗憾的是,服务器之间的时间可能是不同的,存在着时钟偏差的问题。如果存在这种情况,那么,请求将会被阻塞或者立即被拒绝,从而导致服务停止;
- Timeout(超时):传递允许服务等待的时间。这个问题有点棘手,和之前一样,你需要尽快设定截止时间。接下来,任何一个下游服务都应该对自身处理过程进行计时,并从设定的超时时间中减去这个时间,然后传递给下一个服务。重要的是不要忘记进入请求队列等待的时间。因此,如果服务A允许等待400毫秒,而调用服务B花费150毫秒,则在调用服务C时必须告知有250毫秒的超时时间限制。虽然它没有把传输时间也计算在内,但截止时间只能在之后而不是更早的时间触发,因此,这可能会消耗更多的资源,但不会影响结果。在GRPC(Google开发的高性能、通用的开源RPC框架)中的截止日期就是这样实现的。
最后我们要讨论的是,当超过了截止时间时,不去中断调用服务链是否有意义,答案是肯定的,如果你的服务有足够的处理资源,并且在完成请求之后会使其更活跃(缓存/JIT),那么让其继续处理就可以了。
限流器
前面讨论的模式主要解决了级联失效的问题,依赖服务在其依赖关系崩溃后也随之崩溃,最终导致整个服务完全宕掉的情况。现在,让我们来讨论一下当你的服务出现过载的情况。有很多技术方面的原因可能会导致服务过载,那么,现在我们就假设发生了这种情况。
每个应用程序都有其未知的处理极限。这个值是动态的,取决于多个变量,例如近期的代码更新、正在运行的CPU的模式、主机的繁忙程度等等。
当负载超过极限时会发生什么呢?通常,这种恶性循环会出现在如下的情况里:
1. 响应时间增加,GC占用空间增加;
2. 客户端出现了越来越多的处理超时,甚至承担了更多的负载量;
3. 比1的情况更严重;
这里有个例子。当然,如果客户端有错误重试机制或者熔断机制,第二种情况可能不会产生额外的负荷,从而会获得一个跳出的机会。其它的情况可能会发生,从负载均衡的上游列表中删除实例可能会在加载和剔除相邻实例等方面导致更多的不平衡。
对于限流器,它们的做法是优雅地拒绝新的请求,这就是理想情况下应该如何处理过度负载:
1. 限流器将额外的负载量降到可承受的范围以内,从而使应用程序能够根据SLA进行服务请求;
2. 过多的负载被重新分配到其它的实例,或者进行集群的自动/被动缩放;
有两种类型的限流器:速率和并发。前者用来限制允许的请求数量,后者用来限制在任何时刻同时处理的最大请求数量;
为了简便起见,假设对服务的所有请求在计算资源的消耗上是一致的,并且具有相同的权重。不同的用户会有不同数量的数据,例如喜欢的电视节目或者以前的订单等等。通常,采用分页技术有助于实现请求在计算资源消耗上的相等。
限流器使用的更广泛,但并不像并发限制那样能提供强大的保证,所以如果你希望选择一个的话,建议坚持使用并发限制机制,原因如下。
在配置限流器的时候,我们认为会强制执行如下的操作:
服务可以在任何时间点进行每秒N个请求的处理。
但实际上,我们想要说的是:
假设响应时间相同,那么在任何时间点服务都可以进行每秒N个请求的处理。
为什么这句话这么重要?我会用直觉来“证明”。而对于那些愿意用数学来证明的人,查一下什么是排队理论。
假设限流器设置为1000rps,响应时间为1000毫秒,SLA为1200毫秒。在给定的SLA的条件下,我们很容易算出,在1秒钟内服务能同时处理1000个请求。
现在,响应时间增加了50毫秒(依赖的服务开始处理额外的工作)。从现在起,由于请求数超过了处理能力,在每1秒服务都将面临同时需要处理越来越多的请求。如果线程的数量不受限制的增长,那么就意味着你的资源将会被一点一点的耗尽,并直至系统崩溃,尤其是在应用程序的线程1:1地对应到操作系统线程的时候。如何能处理1000个请求的并发限制呢?它可以服务于1000/1.05=~950个RPS,而不会违反SLA协议,然后放弃其余的请求。另外,还不需要重新进行配置。
我们可以在每次服务的依赖关系发生变化时更新流量限制,但这是一个巨大的工作量,可能需要在每次变化时对整个生态系统进行重新配置。
根据阈值的设置方式,它可以分为静态的和动态的。
静态的限流
在这种情况下,限制范围是通过手动进行配置的。阈值可以通过定期的性能测试来评估。然而它不可能是100%准确的,另外,对于安全性来说,可能也会有一定的影响。这种类型的限制要求围绕CI/CD(持续集成/持续交付)管道来进行工作,而且资源利用率也较低。静态的限流器可以通过限制工作线程池的大小(仅限并发)、添加可以计算请求数量的请求过滤器、以及NGINX limiting functionality或envoy sidecar proxy来实现。
动态的限流
在这里,限制取决于度量,度量是在规则的基础上重新计算的。很有可能的是服务过载与响应时间变长之间存在着相关性。如果是的话,度量可以是响应时间的统计函数,例如百分比、中等或平均值。还记得计算等式属性吗?这个属性是更精确计算的关键。
然后,定义一个术语用于表示度量是否正常。例如,p99≥500ms被认为是服务不正常,因此应降低限制范围。如何增大和减小限制范围应该由一个请求反馈控制算法来决定,如AIMD(Additive Increase Multiplicative Decrease,在TCP协议中使用)。下面是它的伪代码:


如你所见,限制的范围增大缓慢,检测应用程序是否运行良好,如果发现错误行为则急剧减小。
Netflix开创了动态限制的思想,并且开源了解决方案,这里是代码库:
https://github.com/Netflix/concurrency-limits。它实现了几种反馈算法、静态限流器的实现、GRPC集成和Java servlet集成。
就说到这里吧,希望你从本文里学到一些有帮助的内容。我想指出的是,上述所说的并不是尽善尽美的,你还应该具有良好的观察能力,因为在实际应用的过程中,可能会发生一些意想不到的问题,需要你能更好地了解当前应用程序的情况。不管怎么样,实现上述这些方法,将有助于解决你当前出现的或者是潜在的一些问题。
原文链接:
https://itnext.io/5-patterns-to-make-your-microservice-fault-tolerant-f3a1c73547b3
本文为CSDN翻译文章,转载请注明出处。
相关推荐
-

微服务权限设计(微服务解决什么问题)
聊技术,不止于技术应用拆分微服务后,一个不可避免的问题就是权限问题.拆分后的各个微服务如何处理权限,怎么处理才能保证满足业务的需求,怎么处理才能保持架构的简单及可维护?今天的文章,让我们来深入微服务架 ...
-
微众银行APP:用服务设计打造未来银行
一.移动互联网开启了新金融时代 为了探索移动互联网的普及以及用户对金融服务的需求变化,在2017年腾讯用户研究与体验设计部(简称CDC)联合国内28家银行进行了一次行业大调研.在这次调研中我们发现不少 ...
-
win10服务主机本地系统占内存高怎么解决?
win10服务主机本地系统占内存高的解决办法 操作方法 01 合理设置Windows Defender计划扫描.Windows Defender是Win8.Win10系统内置的杀毒软件,但是默认Win ...
-
win10 服务主机:本地系统占内存高
win10 服务主机:本地系统占内存高:按网上找的各种方法都试过了,几乎无解! 禁什么windiws searchsuperfetchwindows defender windows update 虚 ...
-
波导微网站功能介绍 波导微我是什么?
波导微网站是由波导股份全资子公司上海波导信息技术有限公司开发,有雄厚的技术团队作后盾,拥有几十年的手机品牌经验,精通软硬件的开发和移动互联网的趋势。波导股份是上市公司,可以为商家提供更智能、更便捷的微 ...
-
微信微务宝是什么?微务宝有什么用?微信微务宝功能介绍
微务宝是微信公众账号管理和营销平台,微务宝平台包含了微网站、会员中心、商家管理、智能客服、微信商城、互动游戏、聊天密室、辅助插件等功能板块,让企业的微信公众账号使用更智能、功能更强大。企业通过“微务宝 ...
-
腾讯微云如何分享链接?微云分享加密和不加密链接的方法
微云是腾讯公司为用户精心打造的一项智能云服务, 您可以通过微云方便地在手机和电脑之间,同步文件.推送照片和传输数据,进行文件资源共享.那么,腾讯微云如何分享链接?接下来小编就把腾讯微云分享文件链接的方 ...
-
微云同步盘和微云区别有哪些? 微云同步盘和微云功能区别对比
微云同步盘和微云的区别是哪些呢?如果你想要知道微云同步盘和微云功能区别的话可以来看下文哦~很多朋友搞不清楚这两款软件究竟有什么不同,看完下文就知道咯~ --微云同步盘特点 微云同步盘的特点是,全自动同 ...
-
微聚是什么软件?微聚如何关注好友?
微聚是什么?微聚是基于地理位置的陌生人约会交友应用,微聚每天可以帮助认识有趣的人和事,是身边丰富多彩的线下活动中心。微聚怎么关注好友呢?一起看看看看微聚关注好友的方法吧!(相关教程:微聚注册方法详解) ...
