常用图像标注方法有哪些(常见的图像标注类型有哪些)
数据标注干货/新鲜AI资讯尽在——
微信公众号【数据标注星球】
图像标注就是将标签附加到图像上的过程。这可以是整个图像的一个标签,也可以是图像中每一组像素的多个标签。
市场对图像标注精准度愈发严格,同时针对不同的应用场景,也衍生出了不同的图像标注方法。
语义分割
语义分割是指根据物体的属性,对复杂不规则图片进行进行区域划分,并标注对应上属性,以帮助训练图像识别模型。语义分割则需要按照语义用自定义画框对交通场景中的图片进行分区,区分出图片中的行人、车辆、道路、标识、树木、建筑物等。常应用于自动驾驶、人机交互、虚拟现实等领域。

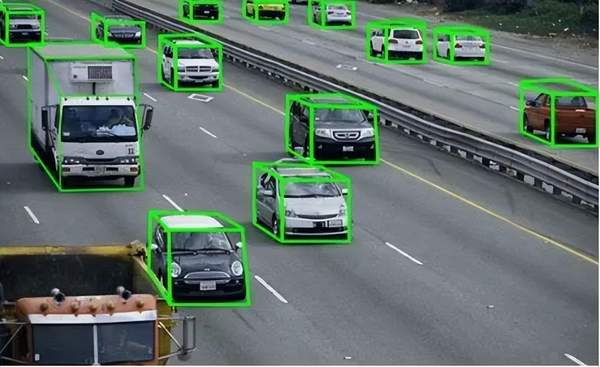
矩形框标注
矩形框标注又叫拉框标注,拉框标注是图像标注中极为常见的一种任务类型,主要是指用2D框、3D框、多边形框等标注出图像中的指定目标对象。

多边形标注
多边形标注是指在静态图片中,使用多边形框,标注出不规则的目标物体,相对于矩形框标注,多边形标注能够更精准地框定目标,同时对于不规则物体,也更具针对性。
关键点标注
关键点标注是指在目标对象的规定位置打上关键点,例如在人脸图片上用点标注出眼角、鼻尖、嘴角等关键位置或者在人体图像上标出骨骼或穴位的位置等。

立方体标注
将2D图片中的车辆进行3D标注,主要应用于训练自动驾驶对会车或超车车辆的体积判断。
3D点云标注
3D点云标注是指从激光雷达采集的点云图中找出目标对象,并以立方体框的形式标注出来,其中包括车辆、行人、广告标志和树木等。
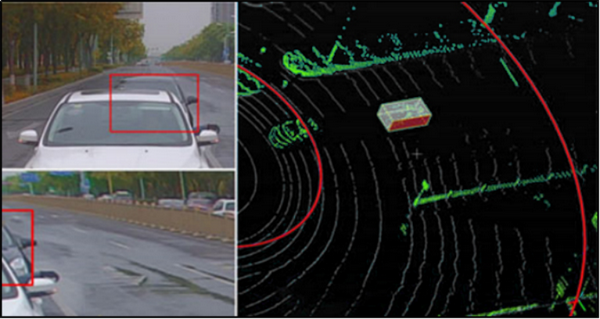
2D/3D融合标注
2D/3D融合标注是指同时对2D和3D传感器所采集到的图像数据进行标注,并建立关联。该方法能够标注出物体在平面和立体中的位置和大小,帮助自动驾驶模型增强视觉和雷达感知。
目标追踪
目标跟踪是从视频数据中按帧捕捉某一对象,并进行画框标注。在军事制导、视频监控、机器人视觉导航、人机交互,以及医疗诊断等许多方面有着广泛的应用前景。
OCR转写
OCR转写是对图像中的文字内容进行标记与转写,帮助训练和完善图片与文本识别模型。
属性判别
属性判别是指通过人工或机器配合的方式,识别出图像中的目标物体,并将其标注上对应属性。
来源:公众号【数据标注星球】