如何将html转为pdf(html网页可以转化为pdf吗)
在本文中,我将展示如何使用 Node.js、Puppeteer、headless Chrome 和 Docker 从样式复杂的 React 页面生成 PDF 文档。

背景:几个月前,一个客户要求我们开发一个功能,用户可以得到 PDF 格式的 React 页面内容。该页面基本上是患者病例的报告和数据可视化结果,其中包含许多 SVG。另外还有一些特殊的请求来操纵布局,并对 HTML 元素进行一些重新排列。因此与原始的 React 页面相比,PDF 中应该有不同的样式和额外的内容。
由于这个任务比用简单的 CSS 规则解决要复杂得多,所以我们先探讨了可能的实现方法。我们找到了 3 个主要解决方案。这篇博文将指导你了解它们的可能性并最终实施。
目录:
- 在客户端还是服务器端生成?
- 方案1:从 DOM 制作屏幕截图
- 方案2:仅使用 PDF 库
- 最终方案3:Node.js、Puppeteer 和 Headless Chrome
- 样式控制
- 将文件发送到客户端并保存
- 在 Docker 中使用 Puppeteer
- 方案3 1:CSS打印规则
- 总结
在客户端还是服务器端生成?
在客户端和服务器端都可以生成PDF文件。但是让后端处理它可能更有意义,因为你并不想耗尽用户浏览器可以提供的所有资源。
即便如此,我仍然会展示这两种方法的解决方案。
方案1:从 DOM 制作屏幕截图
乍一看,这个解决方案似乎是最简单的,事实证明的确是这样,但它有其自身的局限性。如果你没有特殊需求,例如在 PDF 中选择文本或对文本进行搜索,那么这就是一种简单易用的方法。
此方法简单明了:从页面创建屏幕截图,并把它放到 PDF 文件中。非常直截了当。我们可以使用两个包来实现:
- Html2canvas,根据 DOM 生成截图
- jsPdf,一个生成PDF的库
开始编码:
npm install html2canvas jspdf
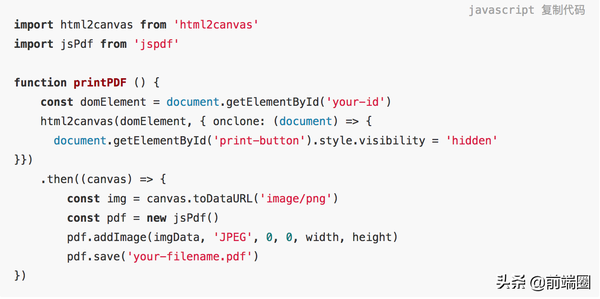
就这样!
请注意 html2canvas 的 onclone方法。当你在截图之前需要操纵 DOM(例如隐藏打印按钮)时,它是非常方便的。我看到过很多使用这个包的项目。但不幸的是,这不是我们想要的,因为我们需要在后端完成对 PDF 的创建工作。
方案2:只使用 PDF 库
NPM上有几个库,如 jsPDF(如上所述)或PDFKit。他们的问题是,如果我想使用这些库,我将不得不重新调整页面结构。这肯定会损害可维护性,因为我需要将所有后续更改应用到 PDF 模板和 React 页面中。
请看下面的代码。你需要亲自手动创建 PDF 文档。你需要遍历 DOM 并找出每个元素并将其转换为 PDF 格式,这是一项繁琐的工作。必须找到一个更简单的方法。
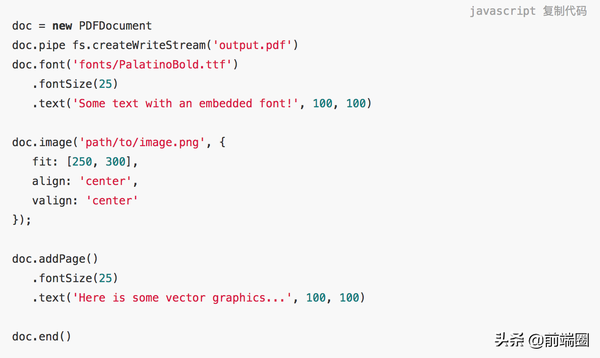
这段代码段来自 PDFKit 文档。但是如果你的目标是直接生成一个 PDF 文件,而不是对一个已经存在的(并且不断变化的)HTML 页面进行转换,它还是很有用的。
最终方案3:基于 Node.js 的 Puppeteer 和 Headless Chrome
什么是 Puppeteer?其文档中写道:
Puppeteer 是一个 Node 库,它提供了一个高级 API 来控制 DevTools 协议上的 Chrome 或 Chromium。 Puppeteer 默认以 headless 模式运行 Chrome 或 Chromium,但其也可以被配置为完整的(non-headless)模式运行。
它本质上是一个可以从 Node.js 运行的浏览器。如果你读过它的文档,其中首先提到的就是你可以用 Puppeteer 来生成页面的截图和PDF。优秀!这正是我们想要的。
先用 npmi i puppeteer 安装 Puppeteer,并实现我们的功能。
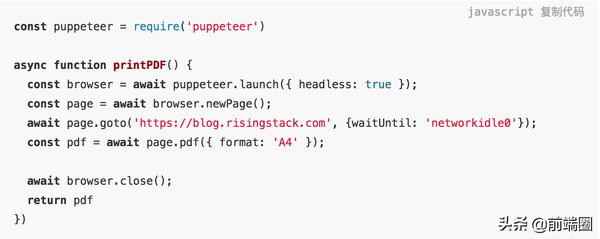
这是一个简单的功能,可导航到 URL 并生成站点的 PD F文件。
首先,我们启动浏览器(仅在 headless 模式下支持 PDF 生成),然后打开新页面,设置视口,并导航到提供的URL。
设置 waitUntil:'networkidle0' 选项意味着当至少500毫秒没有网络连接时,Puppeteer 会认为导航已完成。 (可以从 API docs 获取更多信息。)
之后,我们将 PDF 保存为变量,关闭浏览器并返回 PDF。
注意:page.pdf 方法接收 options 对象,你可以使用 'path' 选项将文件保存到磁盘。如果未提供路径,则 PDF 将不会被保存到磁盘,而是会得到缓冲区。(稍后我将讨论如何处理它。)
如果需要先登录才能从受保护的页面生成 PDF,首先你要导航到登录页面,检查表单元素的 ID 或名称,填写它们,然后提交表单:

要始终将登录凭据保存在环境变量中,不要硬编码!
样式控制
Puppeteer 也有这种样式操作的解决方案。你可以在生成 PDF 之前插入样式标记,Puppeteer 将生成具有已修改样式的文件。
await page.addStyleTag({ content: '.nav { display: none} .navbar { border: 0px} #print-button {display: none}' })
将文件发送到客户端并保存
好的,现在你已经在后端生成了一个 PDF 文件。接下来做什么?
如上所述,如果你不把文件保存到磁盘,将会得到一个缓冲区。你只需要把含有适当内容类型的缓冲区发送到前端即可。

现在,你只需在浏览器向服务器发送请求即可得到生成的 PDF。

一旦发送了请求,缓冲区的内容就应该开始下载了。最后一步是将缓冲区数据转换为 PDF 文件。

就这样!如果单击“保存”按钮,那么浏览器将会保存 PDF。
在 Docker 中使用 Puppeteer
我认为这是实施中最棘手的部分 —— 所以让我帮你节省几个小时的百度时间。
官方文档指出*“在 Docker 中使用 headless Chrome 并使其运行起来可能会非常棘手”*。官方文档有疑难解答部分,你可以找到有关用 Docker 安装 puppeteer 的所有必要信息。
如果你在 Alpine 镜像上安装 Puppeteer,请确保在看到页面的这一部分时再向下滚动一点。否则你可能会忽略一个事实:你无法运行最新的 Puppeteer 版本,并且你还需要用一个标记禁用 shm :
const browser = await puppeteer.launch({
headless: true,
args: ['--disable-dev-shm-usage']
});
否则,Puppeteer 子进程可能会在正常启动之前耗尽内存。
方案 3 1:CSS 打印规则
可能有人认为从开发人员的角度来看,简单地使用 CSS 打印规则很容易。没有 NPM 模块,只有纯 CSS。但是在跨浏览器兼容性方面,它的表现如何呢?
在选择 CSS 打印规则时,你必须在每个浏览器中测试结果,以确保它提供的布局是相同的,并且它不是100%能做到这一点。
例如,在给定元素后面插入一个 break-after 并不是一个多么高深的技术,但是你可能会惊讶的发现要在 Firefox 中使用它需要使用变通方法。
除非你是一位经验丰富的 CSS 大师,在创建可打印页面方面有很多的经验,否则这可能会非常耗时。
如果你可以使打印样式表保持简单,打印规则是很好用的。
让我们来看一个例子吧。
@media print {
.print-button {
display: none;
}
.content div {
break-after: always;
}
}
上面的 CSS 隐藏了打印按钮,并在每个 div 之后插入一个分页符,其中包含content 类。有一篇很棒的文章总结了你可以用打印规则做什么,以及它们有什么问题,包括浏览器兼容性。
考虑到所有因素,如果你想从不那么复杂的页面生成 PDF,CSS打印规则非常有效。
总结
让我们快速回顾前面介绍的方案,以便从 HTML 页面生成 PDF 文件:
- 从 DOM 产生截图:当你需要从页面创建快照时(例如创建缩略图)可能很有用,但是当你需要处理大量数据时就会有些捉襟见肘。
- 只用 PDF 库:如果你打算从头开始以编程方式创建 PDF 文件,这是一个完美的解决方案。否则,你需要同时维护 HTML 和 PDF 模板,这绝对是一个禁忌。
- Puppeteer:尽管在 Docker 上工作相对困难,但它为我们的实现提供了最好的结果,而且编写代码也是最简单的。
- CSS打印规则:如果你的用户受过足够的教育,知道如何把页面内容打印到文件,并且你的页面相对简单,那么它可能是最轻松的解决方案。正如你在我们的案例中所看到的,事实并非如此。
虽然今天是愚人节,但是以上所有内容都是在真的!
作者:疯狂的技术宅
链接:
https://juejin.im/post/5ca1dc0251882543d569e075
相关推荐
-

电脑Edge浏览器软件中网页如何保存成PDF文件
有的小伙伴想要把网页保存成PDF文件,但是却不知道怎么进行操作,其实我们可以在Edge浏览器软件中进行操作,那么具体步骤,小编就来为大家介绍一下吧.具体如下:1. 第一步,双击或者右击打开Edge浏览 ...
-
PDF和网页HTML格式怎么进行互相转换
今天给大家介绍一下PDF和网页HTML格式怎么进行互相转换的具体操作步骤.1. 一.网页转成PDF其实网页转成PDF的方式不止一种,就跟大家演示比较简单的一种.首先将我们想要打印的网页打开,然后在网页 ...
-
如何通过网页在线工具合并PDF文档
PDF是现在十分常用的文件类型之一,有些新用户不知道如何通过网页在线工具合并PDF文档,接下来小编就给大家介绍一下具体的操作步骤.具体如下:1. 首先第一步打开电脑浏览器,根据下图所示,搜索并进入PD ...
-
怎么将网页转化为pdf(网页上PDF文件下载不下来)
平时不管我们是在网上浏览网页,还是查找资料时,我们都会在遇到一些自己感兴趣的内容,而将这些内容保存下来,才能够方便日后我们有时间的时候进行查看. 尤其是在需要打印考证时的准考证.资格证书,又或者是查看 ...
-
如何打印网页(或保存为PDF)
如何打印网页(或保存为PDF)呢?下面小编来教大家,大家一看肯定便会了. 操作方法 01 首先,我们点击打开我们电脑上面的浏览器,然后进入一个网页,进入网页后,我们点击右上角的文件: 02 弹出的界面 ...
-
pdf编辑器哪个好用(pdf文件编辑不了怎么办)
作为办公室的"文件小达人",没两个拿得出手的PDF编辑器还怎么保住我的达人身份?一说到 PDF 编辑,很多人都头疼不已, 不知道该怎么操作,例如怎么给 PDF 加水印.加注释?如何 ...
-
PDF 全面接触 最好用的PDF软件汇总
[转载请保留]出处:http://blog.sina.com.cn/s/blog_46dac66f010002a8.html 本文旨在介绍最实用的、以免费软件为主的PDF工具。即介绍有质量的软件,而非 ...
-
如何将网页内容转化为PDF
word实现法 1这里推荐使用的word版本为word2007或者2010版本。word2003的效果可能跟原来的网页会有差别 2首先,我们拖拽鼠标,选择网页中我能需要保存成文档的内容。右击选择复制 ...
-
互盾pdf阅读器文件怎么转换pdf
互盾pdf阅读器文件怎么转换pdf 一.打开互盾PDF阅读器官网,如图所示. 二.点击网页上的"文件转PDF",将会跳转到一个pdf转换页面. 三.用户可以选择文件转换成pdf的格 ...
