如何使用Power Query批量抓取韩剧下载地址
因为疫情宅在家里,除了刷刷头条,看看抖音,如果你是韩剧迷,有大把的时间可以来追剧。现在最火的是孙艺珍的《爱的迫降》,但是哪里找资源是个问题。

电视上基本上是看不到韩剧的,只有在网络上找资源了,网络上韩饭的网站很容易找到,还有个问题就是,一个一个的去翻看网页太麻烦,最好是自动找到链接地址。那就要用到Power Query的网络抓取功能了。Power Query网络抓取分四步:网站分析、试抓、自定义函数、抓取,我们还是按照这四个步骤进行。
网站分析
网址可以直接修改页码访问,在检查中也能正常预览,地址栏的网址就是真实网址,这就好办了。
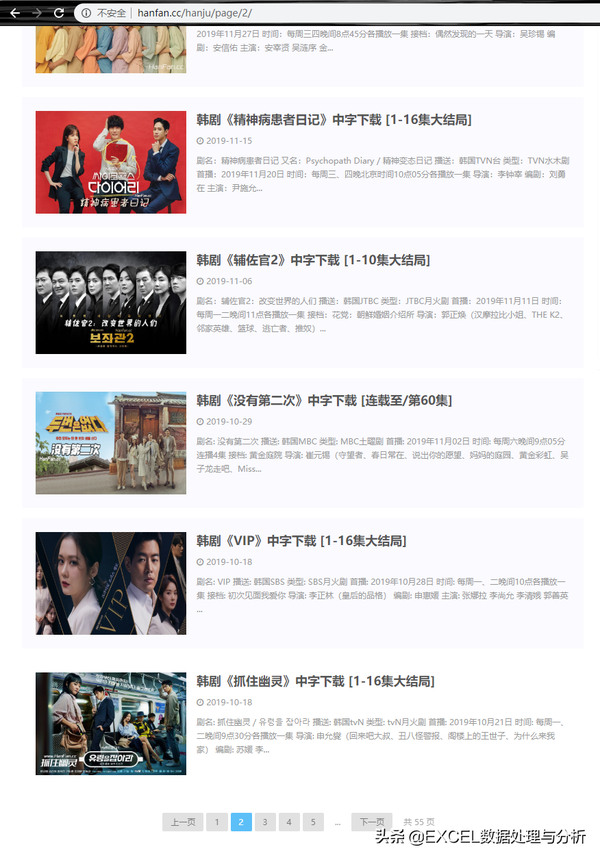
进入到具体的剧集中,有下载地址,点击后有弹窗,里面显示了具体的下载连接,我们通过检查发现:

连接地址是可以找到的。
通过上面的分析,我们可以理清一个抓取的思路:
- 首先要根据页码逐个找到每个韩剧的名称和对应的网址
- 然后根据韩剧地址找到下载地址
就这么简单,抓取过程中可能需要两个函数,一个是根据页码抓网址的函数,一个是根据网址抓下载地址的函数。
试抓
试抓的过程会比较复杂,很多时候最初的试抓过程,并不能解决所有问题,甚至是大部分的问题,原因就是我们没有找到一个最佳的共同特性。我们先来试抓网址:
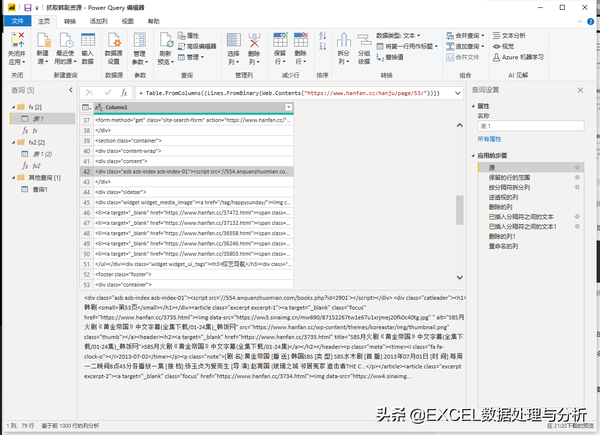
每页中的韩剧内容保存在一行里,这个比较少见,多数时候是一个表单,好在这个网页的格式非常固定,韩剧网址所在的行也是固定不变的,我们在第二步直接就保留一行就好了。这个方法在下载地址试抓中我也用了,后来发现那个下载地址网页内容极不规范,最后用了筛选行。
有时候大家看到一堆的html源码就慌了,其实html要想整齐的显示出来,代码必然也是有规律可循的,我们看页面中一页有12部韩剧,那么我们只要分成12列就好了,关键在于分列的分隔符用什么比较好?通过观察我们发现一部韩剧被认为是一个article,结尾的位置都有我们就用它来分列就好了。
分列后逆透视,变成一列,然后提取网址和韩剧名称,这个过程我也是试了好几次,最后在整个抓取结束后,发现提取的还是有些问题,有些网址没有提取出来,有些韩剧名称没有提取出来,有返回到这一步,再次尝试,我用的是提取分隔符之间的文本,就是要找到网址前的"ref=",网址后的“.html”,以及韩剧名称前的“title=”,韩剧名称后面的“”。
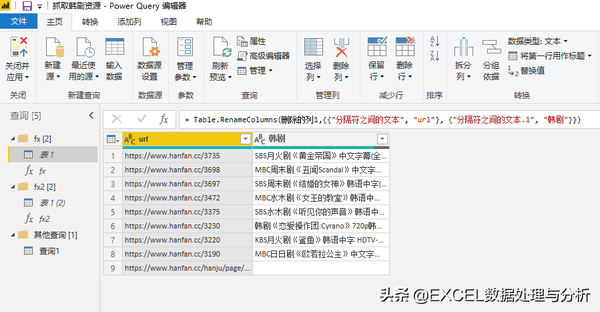
韩剧网址的试抓基本完成了,当然我实际上是反复修改了几次才可以的。
下载地址试抓,不要想着一次就成,因为网站维护估计不是一个人完成的,不同的人写代码习惯不同,就是同一个人,还有手误的时候,下载地址中提取码,有时就是密码,好在都有一个“码”字。

这个过程与韩剧网址抓取过程差不多,就是第二步我们用了筛选,没用保留行,再有就是提取分隔符之间的文本,用到的分隔符不同,基本步骤一致。
自定义函数
在试抓好的查询上右键,选择创建函数:
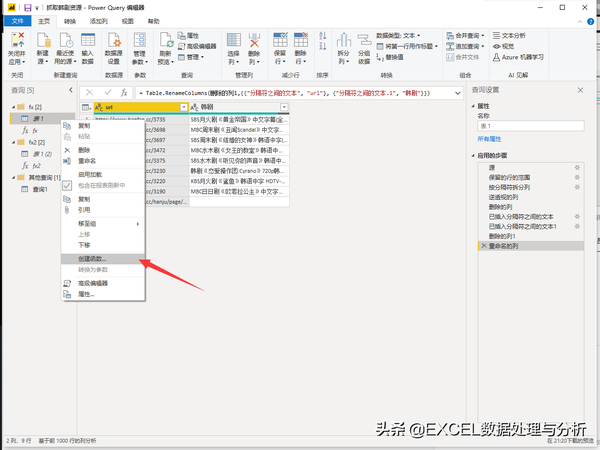
打开高级编辑器,修改函数参数:
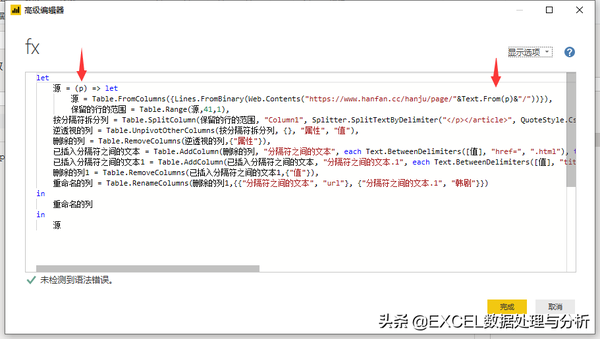
韩剧网址抓取函数,我们用p做为页码参数。

下载地址抓取函数,我们用url作为参数。
抓取
建一个空查询,输入一个55行的列表:
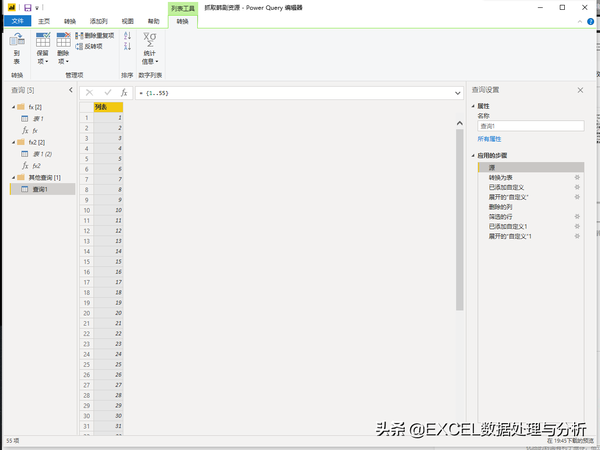
自定义列引用韩剧网址抓取函数,抓取韩剧名称和网址:

展开:
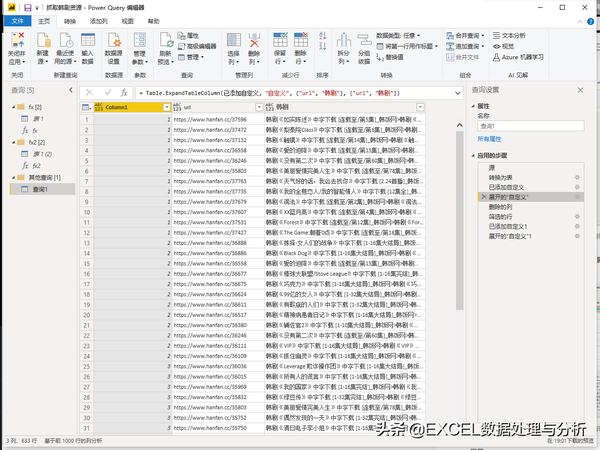
在这一步就有可能发现问题,看看预览中网址是不是都有,韩剧名称有没有空白,如果有,就找到对应的页码,回到试抓那一步,修改页码查看试抓步骤中,哪一步有问题,看看有没有能够统一的解决办法。找到解决方法后,修改自定义函数,在来刷新就能看到修改后的效果了。
即使多次修改,仍然有部分网址空白,或者韩剧名称空白,那么就要筛选掉空白行,避免下载地址抓取时出错。我这步有一行韩剧名称空白,对应的网址是页码,所以就直接筛选掉了。
再自定义列引用下载地址抓取函数,并展开:

这一步可能出现的结果和上一步差不多,如果大面积的空白,就表示下载地址抓取函数定义的不成功,要返回试抓过程做修改,再来刷新,看结果。
相关推荐
-
1号店商品批量抓取
现在人家的生活质量越来越高,在网店中,面对越来越挑剔的买家,你只有从细节上下足功夫,才能吸引买家的注意力,这个细节最重要的莫过于宝贝详情页了.那么卖家们想要在多个不同的店铺中上传这些优秀的详情页,就必 ...
-
批量抓取美丽说宝贝
很多的网店的商品详情页做的非常的好,大家都知道现在购物,口碑营销多么重要,如果一款宝贝,可以配上诸多好评的图片,那么无形的增加了商品的说服力,可以大大的提高商品转化率. 像美丽说平台中的商品详情页都做 ...
-
淘宝如何批量抓取别人店铺的商品
很多淘宝店铺卖家都会选择代销别人店铺的商品,这样会节省很多中间成本.那么如何快速将别人店铺的商品快速搬家到自己店铺呢? 操作方法 01 找到你想复制的店铺商品,然后将链接记录下来.找到抓取商品将这个商 ...
-

商家店铺批量下载抓取淘宝、天猫、1688主图视频如何操作
如今,越来越多的商品都拥有主图视频,因而,如果自己的店铺商品没有相应的主图视频,一定程度上意味着会失去一部分引流渠道.下面,小编就为大家来介绍批量抓取主图视频的小技巧.具体如下:1. 首先在自己使用的 ...
-
怎么抓取彩票开奖结果数据
本为大家介绍如何用爬虫批量抓取彩票开奖结果数据 操作方法 01 步骤一:下载安装并注册登录 1.打开官网,下载并安装爬虫软件 2.点击注册登录,注册新账号然后登录 02 步骤二:新建采集任务 1.复制 ...
-
淘宝商家怎么抓取、下载商品的主图视频的步骤?
淘宝平台的为了能提升客户的购物体验,推出一个主图视频,商家可把商品做成视频,让客户可以多方面的了解商品的多角度的效果,而主图视频,不是每个商家都会做的,所以抓取商品的主图视频上传是代发商家和新手商家最 ...
-
如何抓取淘宝店铺宝贝
如何抓取淘宝店铺宝贝?甩手工具箱的抓取商品功能,可以批量一键抓取您所需的宝贝商品,不管是标题.主题.描述.销售属性及属性图统统都能完整的抓取下来.可以保证所抓取的商品和之前的商品是一模一样. 甩手工具 ...
-
淘宝抓取商品工具使用攻略
如今开网店的朋友日益增多,许多网店店主不仅仅只拥有一个店铺,而对于这些网店店主们就想实现不同店铺宝贝商品的分销.那么这个时候就需要宝贝商品抓取工具来实现从A店铺抓取商品到B店铺了.甩手工具箱的抓取商品 ...
-
最简单的直播源抓取方法
这个抓取直播源的方法很简单,唯一比较麻烦的就是要从一系列的链接中找到直播源的地址链接,使用的软件是URLHelper,原理就是传统的嗅探方法,将电脑网络端口的所有传输数据全部抓取,这其中也就包括了直播 ...
-
Linux抓取批量下载地址
视频网站在线播放列表如下图所示: 查看源代码: <div class="fj1"><span>第1集</span><a href="/eschool/vide ...
