利用百度查看网站Robots协议的方法
相信很多小伙伴都有在使用百度,那么在其中我们怎么去查看网站Robots协议呢?方法很简单,下面小编就来为大家介绍。
方法一:
1. 通过输入网址“https://www.baidu.com/”,进入百度搜索引擎页面。

2. 接着,在搜索框中输入任意内容搜索,当出现“由于该网站的robots.txt文件存在限制指令(限制搜索引擎抓取),系统无法提供该页面的内容描述 - 了解详情”这段文字时,点击其中的“了解详情”。

3. 进入了解详情页面后,找到“输入网站”,在其下文本框中输入我们想要了解的网站的网址,这里小编以输入“https://www.baidu.com/”为例。输完后,点击“检测”。

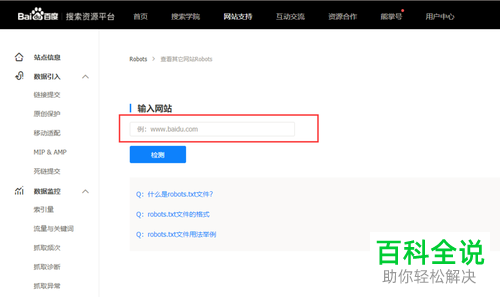
4. 然后其下方就会出现很多脚本语言(如下图红框所圈处),下面小编就来为大家解释一下这些语言的意思。
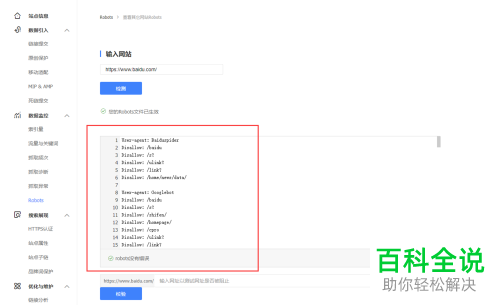
5. “User-agent: Baiduspider”:显示了搜索爬虫的名称,即为“Baiduspider”。同时,代表设置的规则对百度爬虫是有效的。如果出现多个“User-agent:”,则说明有多个爬虫被限制了。
“Disallow: /baidu”:这里显示的是不允许抓取的目录。如果有“/”,则表示所有页面都不允许抓取。
当然,其他的测试链接还有显示“Allow”的可能性,那么是什么意思呢?
“Allow: /s?”:它是用来将某些限制排除的,一般不会单独使用,会和“Disallow”一起出现。
方法二:
在浏览器搜索框中输入网址“https://ziyuan.baidu.com/robots/index”。
方法三:
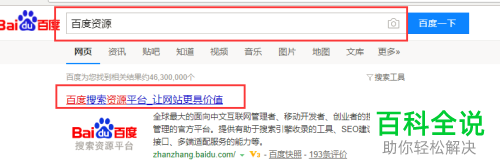
1. 在百度搜索引擎(https://www.baidu.com/)搜索框中输入“百度资源”并搜索,在搜索结果中进入下图红框所圈结果。
2. 在百度资源页面中,点击页面上端的“网站支持”,然后再在其中找到并点击“Robots”。
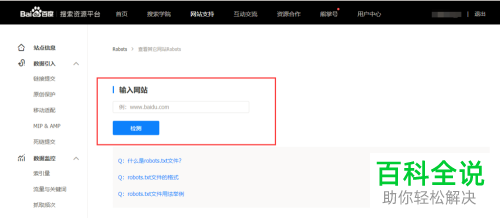
3. 然后就会出现下图所示的Robots文件检测页面。
以上就是小编为大家介绍的利用百度查看网站Robots协议的方法,希望能帮到你~
相关推荐
-
Win7 ghost纯净版系统利用任务管理器查看软件所耗虚拟内存的方法
Win7 ghost纯净版系统利用任务管理器查看软件所耗虚拟内存的方法
-

怎么设置电脑QQ浏览器不允许任何网站处理协议
现在有很多人喜欢在电脑上使用QQ浏览器上网,有些用户想知道怎么设置软件不允许任何网站处理协议,接下来小编就给大家介绍一下具体的操作步骤.具体如下:1. 首先第一步根据下图所示,打开电脑中的[QQ浏览器 ...
-
利用百度电脑专家修复windows系统蓝屏的方法
windows系统下的dll文件通常是保证某些软件与游戏正常运行的重要组件,当系统在出现某些dll文件损坏或丢失时,我们运行软件或游戏,系统将弹窗提示"XXX.dll丢失或损坏"的 ...
-
百度天眼嗅探/摇一摇/查看附近航班使用图文方法
百度天眼是百度对于经常出差坐飞机的朋友推出的一款app,它有几个特色功能很不错,比如嗅探/摇一摇/查看附近航班,下文小编就教大家百度天眼嗅探/摇一摇/查看附近航班的使用方法,还不知道怎么使用的和小编一 ...
-
利用百度地图查看乡、镇行政区域界限地图
如何利用百度地图查看乡.镇行政区域界限地图呢?今天小编为大家讲解一下. 操作方法 01 打开电脑,找到搜狗搜索,点击并进入,如图所示. 02 进入之后,搜索"百度地图",点击并进入 ...
-
怎样利用百度指数查看关键词的热度
利用百度指数我们可以查看一个关键词在当前的网络环境下是否受欢迎,点击量是否足够大,现在就让我们一起来学习下怎样用百度指数查看关键词的热度吧 操作方法 01 在浏览器搜索框中搜索百度指数,在搜到的网页中 ...
-
如何在百度音乐网站下载歌曲伴奏的方法
百度音乐网站如何下载歌曲伴奏呢?一起来看看下面的方法吧 操作方法 01 打开浏览器,搜索"百度音乐" 02 搜索到百度音乐官方网站,点击进入网站 03 进入到百度音乐官网首页,在搜 ...
-
如何用百度统计查看网站浏览信息
首先当然就需要站长在百度统计平台注册一个账号,有一个绑定我们网站的账户. 操作方法 01 打开百度统计页面: 02 2.注册一个百度统计-网站统计帐号 03 这里要说的用户名和密码必须自己保管好,网站 ...
-
在Win7下安装IPX/SPX协议的方法图文详解
windows7局域网不能联机游戏,魔兽争霸局域网看不到主机红警不能进入网络,这是因为windows7系统没有自带IPX/SPX协议,那怎么在Win7下安装IPX/SPX协议呢,下面笔者给大家提供了W ...
