python爬取付费音乐(python爬虫下载付费音乐)

配置基础
Python
Selenium
Chrome浏览器(其它的也可以,需要进行相应的修改)
分析
如果爬取过网易云的网站的小伙伴都应该知道网易云是有反爬取机制的,POST时需要对一些信息的参数进行加密函数的模拟。但是这里为了简便,小白也能理解。直接使用了Selenium来模拟登录,然后使用接口来直接下载音乐和歌词。
实验步骤:
根据歌手ID获取该歌手的热门歌曲列表,歌曲名称和链接,并保存到csv文件中;
读取csv文件,根据歌曲链接,提取歌曲ID,然后利用相应的接口,下载音乐和歌词;
将音乐和歌词保存到本地。

Python实现
该部分将对几个关键的函数进行介绍...
获取歌手信息
利用Selenium我们就不需要看对网页的请求了,直接可以从网页源码中提取相应的信息。查看歌手页面源码可以发现,我们需要的信息在iframe框架内,所以我们先需要切换到iframe:
browser.switch_to.frame('contentFrame')
继续往下看,发现我们需要的歌曲名字和链接是在id="hotsong-list"的标签中,然后每一行对应的是一个tr标签。所以先获取所有的tr内容,然后遍历单个tr。
data = browser.find_element_by_id("hotsong-list").find_elements_by_tag_name("tr")
注意:前一个是find_element,后一个是find_elements,后者返回一个列表。
接下来就是解析单个tr标签的内容,获取歌曲名字和链接,可以发现两者在class="txt"标签中,而且链接是href属性,名字是title属性,可以直接通过get_attribute()函数获取。


下载歌词
网易云有个获取歌词的接口,链接为:
http://music.163.com/api/song...
链接中的数字就是歌曲的id,所以我们拥有歌曲id后,可以直接从该链接下载歌词,歌词文件是json格式,所以我们需要用到json包。

而且直接获取的歌词中,每行有一个时间轴,需要用正则表达式来剔除,完整代码如下:
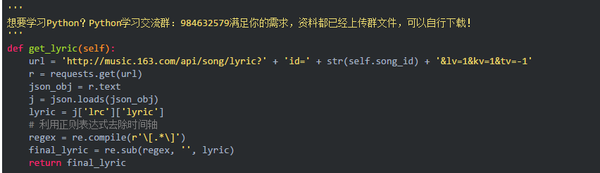
下载音频
网易云也提供了音频文件的接口,链接为:
http://music.163.com/song/med...
链接中的数字为歌曲的id,可以直接根据歌曲的id来下载音频文件。完整代码如下:

相关推荐
-
网易云音乐如何免费下载付费歌曲?
网易云音乐非常好,但是由于目前歌曲版权意识越来越严重,导致很多歌曲都需要付费才能下载呢?但是对于很多人来说,付费下载还是非常贵的.那么,网易云音乐付费歌曲免费下载呢?下面让我来给大家介绍下吧,希望对大 ...
-

如何在酷狗音乐中免费下载付费歌曲
当我们不是酷狗VIP会员却又想下载付费歌曲时,该怎么办?今天小编就来说说下载的方法.具体如下:1.首先,登录并进入非VIP的酷狗音乐账号.2.在搜索框中搜索自己想下载的付费歌曲.3.然后,点击歌曲右侧 ...
-
qq音乐怎样免费下载付费的歌曲?
qq音乐怎样免费下载付费的歌曲,下面就和大家来分享一下,希望可以帮助到大家. 操作方法 01 首先打开qq音乐应用,然后找到需要下载的歌曲. 02 点击歌曲的专辑,找到所属此歌的歌词本. 03 断网后 ...
-
手机怎么将网易云音乐APP中下载的音乐格式更改为MP3
我们在使用网易云音乐下载音乐的时候,一般都不是MP3格式.那么今天小编就跟大家分享一下手机怎么将网易云音乐APP中下载的音乐格式更改为MP3.具体如下:1. 首先我们需要先在网易云音乐中下载一首歌.2 ...
-
虾米音乐APP中下载的音乐文件怎么彻底删除
我们在使用虾米音乐的时候,会下载喜欢的音乐,想要将这些音乐文件彻底删除,释放手机内存,该怎么操作呢?今天就跟大家介绍一下虾米音乐APP中下载的音乐文件怎么彻底删除的具体操作步骤.1. 首先打开手机上的 ...
-
如何将百度音乐播放器下载的音乐保存到桌面上?
对于如何将音乐播放器下载的音乐保存到桌面上,刚开始的时候对一个新手来说想一下子找到应该是很难的.有时候音乐下载完毕了,想立即找到音乐文件还是费时间的,还不如提前设置好,这样方便找到.接下来我把&quo ...
-
网易云音乐如何设置下载的音乐到SD卡上?
网易云音乐是一款很好的音乐播放器,一般小编听音乐常常用的就是这几款,它就是其中的一款,这款音乐播放器说实话呢还是蛮不错的,在里面可以听到很多歌手最新发布的新专辑,今天小编baby_任意依恋给大家带来: ...
-
python网易云音乐爬虫原理(python爬取付费音乐)
在开始之前,做一点小小的说明哈:我只是一个python爬虫爱好者,如果本文有侵权,请联系我删除!本文需要有简单的python爬虫基础,主要用到两个爬虫模块(都是常规的)requests模块seleni ...
-
酷狗音乐中如何下载付费音乐歌曲
今天,小编给大家介绍酷狗音乐中下载付费音乐歌曲的方法,希望对大家有所帮助.具体如下:1. 首先,请大家在自己的手机中找到[酷狗音乐]图标,点击进入主界面,然后选择屏幕左上方的[三]图标按钮.2. 第二 ...
